
1932年7月,在洛杉矶举办的第10届夏季奥林匹克运动会上,一个只有几人组成,运动员仅1人的代表团完成了注册参赛。他们经历了无尽的辗转波折,漫长的海上漂泊,最终来到了奥运赛场上,他们来自——中国。
来到赛场,本身就证明了很多,改变了很多。时至如今,中国的奥运之旅已经跨过了90年。我问文心一言,中国在奥运赛场上取得了哪些成就,它从金牌、奖牌、成绩、覆盖项目四个领域进行了归纳,并总结道,“中国代表团在夏季奥运会上取得了辉煌的成就,金牌数量和奖牌总数均位居世界前列,同时在多个项目中也实现了历史性突破”。

3月16日,当百度向世界展示文心一言的时候,我脑海中首先浮出的是这么一句话:中国AI终于来到了奥运赛场上。
我们为什么会如此期待文心一言?是对技术革命的热忱,对生产力的渴望?这些当然都有,但更加急切的是,对中国科技能否真正参与到这轮科技革命的担忧和焦虑。
文心一言究竟做到了吗?
我们第一时间拿到了文心一言的测试资格,就让我们从最真实的产品表现出发,回溯这条参赛之路。
站在赛场
我相信任何人都不会认为,近期爆火的大语言模型其价值仅仅在问答,它即将引发出的广泛性科技创新是清晰可见的,带来的价值远远超过其基础。
从2012年深度学习技术成型,到2016年因为数据集测试效果优秀与AlphaGO的良好宣传效果,第三次AI崛起正式开启。2018年,预训练大模型出现,经历了数年时间,ChatGPT等应用正式通过大语言模型的形式引爆了技术能量,这可以被看作AI复兴的2.0形态,是当之无愧的时代焦点。
最重要的是这场比赛才刚刚开始,如果能够第一时间参与到全球主流竞争,意味着中国AI可以参与到竞争规则制定,为上下游发展获得先手时机,创造出符合中国经济与社会需求的战略周期。
那么,文心一言拿到这张宝贵的“参赛券”了吗?
3月16日下午,在新闻发布会现场百度创始人、董事长兼首席执行官李彦宏向各界展示了新一代知识增强大语言模型文心一言在文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成五个使用场景中的综合能力。但大家肯定会更加好奇,展示效果之外,文心一言的实测、实用情况究竟如何?
当晚,我们就拿到了文心一言的测试资格,对其进行了全方位“拷打”。话不多说,直接上文心一言与ChatGPT的对比,全程无修改无打码。我们选取了大家最关心的,也是应用度最高的几方面问题进行测试。需要提前说明的是,生成式AI的答案每次都会不同,因此我们的测试结果不一定与其他媒体或用户完全一致。
1.数理逻辑能力
能够理解数理逻辑,回答复杂问题,一直被视作是ChatGPT的最大特色。那么在这方面文心一言能力是否可观呢?我们请出了中国人最熟悉的数理逻辑问题——小学奥数,来为大家解答。以一道非常经典的行程问题为例,文心一言的答案是这样的:

可以看到,答题过程虽然简略,但核心计算过程是非常清晰的,并且答案准确无误,到这里可能效果还没有拉满,那我们不妨看看ChatGPT同一个问题的答案:


嗯,解题过程非常华丽,但最终结果似乎是欺负我没上过小学。事实上,直到如今ChatGPT依旧有大量类似问题,可以概括为“一本正经地胡说八道”。结果经常出错这件事,对于生成式AI的可信度、可用度其实是大打折扣的。相比来说,文心一言显然在逻辑与中文的理解上不落下风。
2.中国文化理解
我们知道,对比一家美国公司的AI模型中国文化理解能力,似乎有失偏颇。但对于中国开发者和用户来说,AI对中国文化和语言的理解就是核心诉求,这点是毫无疑问的。那么,在这个领域上文心一言 vs ChatGPT会有怎样的表现呢?
先来看一个关于唐诗的问题吧。关于李白和王维的艺术风格,ChatGPT是这样回答的:

而同样的问题,文心一言的答案则是这样的:


虽然ChatGPT的回答也很不错,但显然对于李白“诗仙”、王维“诗佛”这个最重要的艺术内核根本没有涉及。无论是知识科普还是专业回答,ChatGPT的答案显然都不能得到高分,而文心一言的回答则更加全面细致,且总结归纳能力更强。
我们再来问一个明清小说的问题,关于《红楼梦》的情节,ChatGPT是这样答的:


而文心一言的答案,似乎从逻辑调理上就与ChatGPT完全不同:


这就又不得不吐槽了。ChatGPT回答的不是“主要情节”,而是“包含哪些内容”。相反,文心一言则确实梳理了主线情节的条理,并且给出了主线与副线关系的理解。在此基础上,对《红楼梦》的内涵做出了具有深度的解析。
对比下来,ChatGPT明显又犯了答非所问的毛病。但不管怎么说,两个AI对于中国文化瑰宝的理解,似乎都值得我们大多数人羡慕和学习。
3.最新信息查询
对于我们大多数人而言,都肯定是希望AI问答能够帮助我们了解世界最近发生的事情,了解那些最新的消息和动态。但ChatGPT即使在升级GPT-4之后,依旧采用了到2021年为止的数据,这也是其广受诟病的一个问题。那么,文心一言能不能接入最新、最近的信息呢?
我最近一直没时间追番,于是问了问文心一言《名侦探柯南》的最新情节:

为了确定这就是最新剧情,我又问了这是哪一期:

可如果同一个问题问ChatGPT,会得到怎样的答案呢?
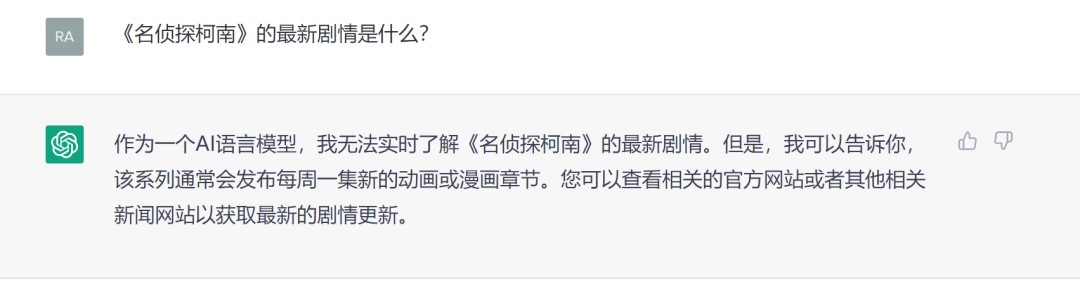
好吧,它委婉的告诉我,想知道就滚去自己看......显然,获取最新的知识、新闻、动态,也构成了文心一言的独特优势。
4.多模态生成
这一点,目前还是文心一言的专属能力,ChatGPT并不具备生成图片的功能。可能有人会认为以文生图有专门的模型。但不可否认的是,合并到同一个问题系统中,带给用户的便捷性是十分明显的。既然ChatGPT还没有类似能力,那我们就让文心一言生成一张图片,结束我们的测试部分:

可以看到,无论对刺客信条还是钢铁侠的理解,文心一言都是能够找到“那个味”的。
至此,我们可以坦然且真诚地说:文心一言或许并不完美,在很多地方与ChatGPT互有短长。但真的有自己的技术优势,更加实用,更加理解中国语言与文化,也更符合中国用户的需求。
文心一言,真的拿到了大语言模型的决赛资格。
水到渠成的参赛之路
那么我们不禁要问,这背后的原因是什么?为什么又是百度抓住了这个至关重要的战略机遇?这里面有什么运气或者玄机吗?答案或许非常简单,仅仅有“水到渠成”四个字。

百度CTO王海峰认为:“做文心一言不是头脑发热,是十余年的技术积累和产业实践的水到渠成,我们在人工智能四层的技术架构上都有很深的积累,尤其是框架层和模型层联合优化发挥了非常大的作用。”
就像芯片是生长在数学、光电与制造业基础上的。文心一言所代表的大语言模型能力,是生长在AI技术积累,尤其是大模型与深度学习框架之上的。
2019年3月,百度就发布了文心大模型ERNIE 1.0。四年时间,已经从最初的自然语言理解大模型,发展成了跨语言、跨模态、跨任务、跨行业的能力完备的大模型平台。在框架方面,百度早在2016年就正式对外开源PaddlePaddle(飞桨),飞桨有效支撑了大模型的灵活开发、高效训练和推理部署,成为了文心一言诞生的底座。
文心一言另一方面的基础来自于数据和知识,百度在搜索引擎端的庞大数据积累、数据精细化处理,以及知识图谱的搭建,最终成为了文心一言的养料。正所谓你看见的是台上一分钟,看不到的是台下十年功,因为百度预判到了全球AI的预判,每一步都在做正确的事,最终才能实现又快、又好锻造出了文心一言。
如果我们把文心一言背后的技术能力进行打开、分解,就可以清晰看到“水到渠成”是如何实现的。
首先,文心一言就像ChatGPT一样,吸收了大语言模型业界公认的领先实现手段。比如有监督的模型精调,确保模型的高鲁棒性和吸收数据能力;类似人类反馈机制的的强化学习,可以实现模型基于用户反馈持续进化,实现“智能涌动”效果;融合不同类型的数据、知识,构造丰富的提示,生成高质量的结果。
这些能力保证了文心一言能够区别于传统的多轮对话模型,满足用户对新型大语言模型的期待,而百度独特的技术才是文心一言焕发技术创新力的核心。
这个领域的技术,主要包括三个维度:
首先是知识增强。知识增强是文心系列大模型的核心技术特征,也自然而然集成到了文心一言当中。即通过引入知识图谱,“知识增强”的方法,将数据与知识融合,使得文心大模型相较于其他模型,学习效率更高、可解释性更好。在文心一言能够实现“知识增强”的背后,是百度构建了包含5500亿事实的全球最大知识图谱,从这里我们也可以看到文心一言与文心系列大模型紧密的关系与一致的技术序列。百度在大模型领域的积累,最终在文心一言完成了厚积薄发。
其次是检索增强。文心一言并入了百度在搜索引擎方面的能力与技术,百度新一代搜索架构已经发展到了基于语义理解和匹配,其中文心大模型分别理解用户输入和文档,形成双塔模型,然后基于理解进行匹配。这让文心一言可以准确获得高时效性的内容,填补了ChatGPT目前为止还无法实现的空白。同时,检索增强也可以优化大模型的推理能力,使它的回答更加精确、有效。
此外,文心一言还加入了百度长期积累的对话增强能力。从而使得大模型具有上下文理解、多轮对话等能力,增强对话的连贯性、合理性。
全球领先的技术范式,需要我们有能力去学习和了解;自身储备的核心技术能力,则可以在关键时刻构筑差异化。二者结合,中国AI才有出路。文心一言背后的技术序列,为中国AI究竟如何发展点亮了方向。
另一方面,文心一言能够在如此快速的时间内完成训练、部署,最终为中国AI抢得了先机,不得不提到背后的开发基座——飞桨。
在框架层,飞桨是百度自主研发的中国首个开源开放的产业级深度学习平台,包括核心框架、产业级模型库、开发套件、工具组件,以及学习和实训社区,能够标准化、自动化地支撑模型生产和应用。在飞桨的配合下,文心一言才能够有效实现大量最新技术的融合,同时在如此短的时间内完成开发、落地。
从中可以看到,百度已经筑造了飞桨+文心,即深度学习开发平台+大模型的产业路径。二者结合,企业和开发者可以获得从算力、框架、模型库,再到大模型调用、大模型行业化的所有能力,得到了完善、稳固的产业智能化基座。
文心一言精、快、好落地的今天,就是更多中国大模型脱颖而出的明天。
中国故事,刚刚开始
大语言模型崛起,乃至更宏大的AI复兴与新一轮科技革命,在文心一言的证明下,应该可以说上一句:中国故事,才刚刚开始而已。
我们知道大语言模型的应用化,可以带来非常多的产业发展可能。其中包括但不限于引领搜索、办公、客服、内容创作等领域的变革;为更多未知应用提供底座,甚至形成用户的超级智能助手。而大模型与行业的融合,则可能带来千行百业的生产力革新。
这些产业可能性的基础,必然是中国具备与全球顶尖水平对齐的AI能力,不能留下短板,不能受制于人。
就像AlphaGO的价值不仅在棋盘上,ChatGPT的价值不仅在问答中。文心一言的价值也不仅仅在百度的业务范畴内,不仅仅是满足一次“中国能不能做大语言模型”的好奇——它的价值在更远的地方。
向后看,文心一言证明了百度乃至更多中国AI公司的技术能力。百度是全球为数不多拥有“芯片层、框架层、模型层、应用层”全栈AI技术能力的公司。这些积累究竟能不能打硬仗,能不能实现与世界一流水平的并排抢跑?这些问题在文心一言这里,也就有了答案。
向前看,中国AI究竟是否能攻坚克难,解决关键技术自主化的时代难题等未知的问题,需要一些火苗,一些希望。
或许,文心一言刚诞生时还不完美。这一方面是因为技术还需要发展,模型还需要进化,需要用户的反馈来不断迭代升级;另一方面,是因为我们对它有着过高的期待,对中国科技有着过高的期待,极高预期之下,没有技术是完美的。
不妨给文心一言一些耐心,给中国AI一些时间。难题从来无法马上被解决,但也只有那些足够艰难,需要漫长时间与精力去破解的难题,才有被解决的必要。
好在,中国AI已经踏上了奥林匹亚的赛场。参赛,就是无数可能性的开始,就是话语权的基座。
会在某一天,未来的某一天,我们回首看,是八千里路云和月。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







