
一夜之间,AI大模型热得发烫。
继3月中旬,百度最先下场,以“文心一言”抢占了对标ChatGPT的“国内第一”后,过去一个月,大模型一直是市场的焦点。尤其是在过去一周里,各界选手纷纷“大干快上”,密集开“卷”,要么直接卷大模型,要么卷产品卷Demo,要么卷预告卷进展。总之,大模型江湖,彻底火起来了。
百度最先挑起战事,阿里、商汤跟得最紧、跑得最猛,都已发布类ChatGPT产品。
不止如此,科大讯飞等中大厂的大模型也已经在发布的路上。而适配到具体场景的应用和产品,比如360的“360智脑”已经进行过现场演示,有赞也带来了由大模型驱动的首个AI产品“加我智能”。就连飞书,也悄悄上线了关于智能助手“My AI”的Demo视频。
就在去年,AI还因为商业化困局而被外界诟病。去年年底,OpenAI的ChatGPT问世,成为了搅动AI大模型江湖的鲶鱼,一时间,各类选手纷纷涌了进来。
被视为是移动互联网时代第一场大战的“千团大战”,至今仍令人记忆犹新,那时,从业者们的信念是,所有的行业都值得用互联网再做一遍。时至今日,阿里巴巴集团董事会主席兼CEO张勇在4月11日已经喊出“所有产品都值得用大模型重做一遍”的口号。尽管当下还处于大模型混战的早期阶段,各家的能力更新,都还没有正式对外开放,对于大厂的大模型能力,还没有一套成熟的评估体系,但是,AI大模型时代的变革,已经开始酝酿。
市场各种信号都昭示着,“百模大战”的帷幕已经拉开。曾经,硝烟弥漫的“千团大战”,结局是一地鸡毛,数千家公司同台竞技,只有美团最终跑了出来,无数公司沦为炮灰。现如今,AI时代的“百模大战”,“入场券”更贵,对于资源、技术、人才的要求更高,也更需要耐心和时间。新选手烧钱烧时间,结果也可能只是巨头的陪跑。这场持久战,才刚刚开始。
百“模”大战,一触即发
大模型江湖混战,愈演愈烈,下场的选手越来越多。竞争最激烈也最受关注的,便是在大模型领域有所积累的互联网巨头选手们。
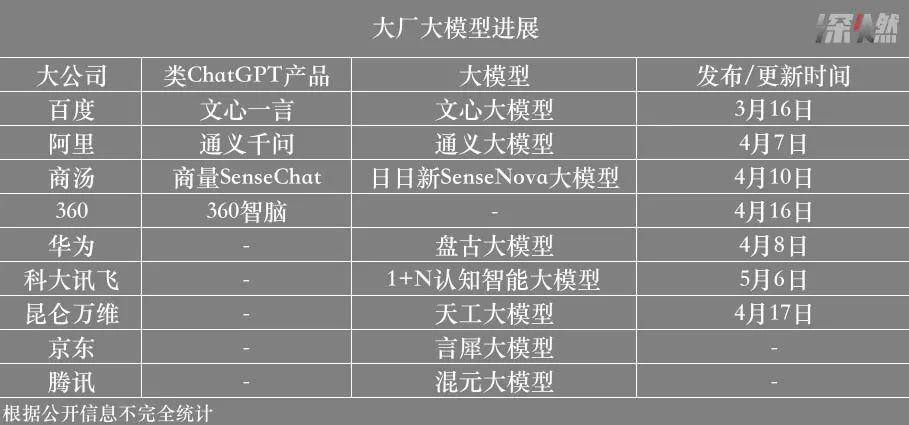
这波混战源起ChatGPT。巨头选手们的类ChatGPT产品以及最新的AI大语言模型首先受到关注。其中,百度3月16日发布了“文心一言”;阿里的“通义千问”已从4月7日开始企业内测;商汤科技在4月10日的技术交流会上带来了“商量SenseChat”,目前还未对外开放;360在3月29日现场演示了“360智脑”后,也将于4月16日开启企业内测。
这些类ChatGPT产品,主打的都是对话问答、文本及代码等生成能力,外界常常会把多轮对话、数学能力、编码能力作为测评的标准。
业界的共识是,国内这些产品相较ChatGPT,还有一定的差距。但是这些产品,究竟孰强孰弱、孰优孰劣,还难下定论,因为尚处于内测或演示阶段。
不过,各家的产品形态有一定差别。比如,尽管文心一言的生成图片能力遭到吐槽,但已经实现了多模态交互;通义千问增加了“百宝袋”,把写提纲、SWOT分析等能力单独列成板块以供使用;360则是直接和搜索引擎场景进行了结合。
与类ChatGPT产品共同进入我们视野的,则是各家的大模型体系。
其中,360的大模型,此前市场关注度并不算高。不过,360称,其人工智能研究院从2020年开始,一直在对包括类ChatGPT在内的大模型通用人工智能技术持续投入。
其余三家中,百度“文心一言”和阿里的“通义千问”,背后分别是此前已经发布过的文心大模型体系和通义大模型体系;商汤“商量SenseChat”背后是最新问世的“日日新SenseNova”大模型体系。三家本质都是在统一AI底座的基础上,在通用模型层覆盖NLP、视觉等领域,再进行行业模型和场景模型的孵化。
深燃制图
文心大模型除了有文心一言、AI作画应用文心一格外,还和工业、能源、金融等多个行业客户共同打造了11个行业大模型。商汤基于大模型体系,还发布了AI内容创作社区平台“秒画”、AI数字人视频生成平台“如影”、3D内容生成平台“琼宇”、“格物”。
接下来,预计最快亮相的选手,当属科大讯飞。其计划于5月6日发布“1+N认知智能大模型”,“1”是底座平台,“N”则是应用于多个行业领域的专用大模型版本,同时,“N”个场景的示范性应用产品也将随之呈现。但是否会有类ChatGPT产品,还不确定。
备受市场期待的选手,还有华为、腾讯、京东、字节跳动,这几家虽然没有大张旗鼓发布基于大语言模型的新产品,但也找机会对外重新梳理大模型体系或透露新进展。
其中,华为云首席科学家田奇在4月8日的一场公开活动上表示,华为盘古大模型在2022年发布NLP大模型、CV大模型和科学计算三个基础大模型之后,又陆续发布行业大模型系列,包括盘古气象大模型、药物分子大模型等等,华为大模型还是坚定走To B的路线。其内部专家此前就曾指出,“华为很少在新的趋势出现后,立马追上”。
腾讯曾于2022年发布混元大模型体系,据透露,目前也在研发类ChatGPT产品;京东4月对外宣称,计划在今年发布新一代产业大模型“言犀”;字节跳动根据公开报道正分别在语言和图像两种模态上发力。
当然,市场上也不乏蹭热点的选手。昆仑万维的大语言模型“天工”3.5,也将于4月17日开启内测。4月11日,深交所向昆仑万维下发关注函,再次提醒不得利用市场热点题材,进行“蹭热点”等违法违规行为。
除了这些大公司之外,根据民生证券相关研报统计,目前国内至少已经有30多家大模型亮相,其中不乏参数规模甚至超过ChatGPT规模的大模型。厂商涵盖了互联网巨头、AI上市公司、服务器龙头企业、科研院所与一级市场创业公司。
大模型应接不暇,新产品层出不穷,ChatGPT风口上的诸神混战才刚刚开始。
抢发大模型,大厂不能错过的一战
大厂混战大模型之际,各家的大模型能力究竟几何,才是最令外界好奇的。以往,大厂选手们做大模型,总是粗暴地拼参数量,业内大模型的参数从百亿进化到了千亿甚至万亿。
现如今,参数量早已不能当作衡量大模型能力的唯一标准。AI领域从业者章容对深燃表示,大模型的能力或许有学术层面的评估,但依然缺乏较为成熟的评估标准和体系。
文心一言发布后,百度创始人李彦宏在3月下旬曾对外表示,文心一言不如最新的ChatGPT版本,但是差距不是很大,可能就是一两个月的差别。就连刚刚下场成立AI公司“百川智能”的搜狗创始人王小川也对外表示,正在研发大模型产品,今年内可能就能追上ChatGPT3.5的水平,至于赶上GPT-4或者GPT-5,可能需要3年左右的时间。
现如今,业界衡量大模型能力最直接的标准,似乎变成了和ChatGPT相比差距有多大,多久能追上,但也只能是模糊对比。
虽然如何评价大模型的实力还没有统一标准。但是,大厂们已经开始展望大模型进入到业务应用层能带来的变革。从目前选手们的参与思路来看,百度、阿里都已经宣布未来主流业务,将与最新的大语言模型深度结合。
在文心一言发布前,李彦宏在内部信中就曾介绍,百度计划将搜索、智能云、自动驾驶多项主力业务与文心一言整合。4月11日的阿里云峰会上,张勇也表示,阿里巴巴所有产品,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等,未来都将接入“通义千问”大模型进行改造。目前钉钉和天猫精灵已经接入测试,新功能将在评估之后发布。
大厂主流业务的改造正在酝酿或进行。而大厂掌握着更多的场景和数据,也能反哺大模型的发展。
在云计算领域,2022年,以天翼云为代表的运营商云加速崛起,而以阿里、腾讯为代表的互联网大厂云计算业务增速放缓,大厂云需要找到新的增长驱动力,张勇甚至下场担任阿里云事业部的一把手。

显然,大模型正在扮演这样的角色。百度、阿里、华为,都是云事业部来做大模型to B、to G的对外服务,云计算市场头部四朵云已经集齐三朵。在大模型时代,正如李彦宏所言,云计算市场的游戏规则正在发生根本性变化。
企业协同办公市场中,疫情以来,钉钉、飞书、企业微信三足鼎立的格局基本形成。而钉钉在4月11日展示了接入“通义千问”的Demo之后,飞书在当天下午也紧急发布了智能助手“My AI”的Demo视频。就如同微软Office 365的Copilot产品,钉钉和飞书的Demo,都或将帮助职场人在工作效率方面实现大幅提升。现在,压力给到了企业微信。
在搜索领域占市场六成份额的百度,要让文心一言改造搜索体验。占据搜索市场三成份额的360紧随其后演示360智脑,被外界认为是,开启了搜索市场争夺战。
同样,商汤、科大讯飞这些曾经的AI大厂,见证了从机器学习到AI大模型时代的变迁,现如今,更是不愿错过大模型的风口。
拥抱大模型,就是拥抱下一个时代。大模型内卷之际,结合场景,基于大模型的产品依然在层出不穷。比如有赞接入GPT-4,上线了“加我智能”。同花顺的AI产品将在4月14日上线,但是否会在其i问财产品的基础上有所创新,还未可知。
“让子弹先飞半年”
“大厂们都是先来占位!”章容称,“因为大模型的能力还远未成熟落地,现在互联网大厂更像是在秀肌肉”。
一位即将进行AIGC创业的AI从业者告诉深燃,大模型就像是AI时代的操作系统,大厂抢先占位,不排除是为了抢客户、抢人才。毕竟,大佬们下场官宣创业,往往伴随着招人。
但更值得注意的是,大模型的能力越强,API可以实现的应用端场景就越丰富,相当于大厂都在争AI时代的“App Store”。
大模型并非一朝一夕就能够炼造的,现如今大厂选手大模型动态层出不穷,本质还是过去几年技术积累的产物。
做大模型,必然伴随着重投入。在国外,微软投资OpenAI,先后投资了超100亿美元,而OpenAI对于GPT-3的训练费用已经超过1200万美元。这一点,从国内大厂的研发投入也可窥一斑。
财报显示,2022年百度的核心研发费用为214.16亿元,占百度核心收入比例达到22.4%。过去10年,百度研发投入超1000亿元。根据商汤财报,过去四年,商汤总营收为149.8亿元,而研发开支则达到了114.3亿元,营收占比达到76.3%。

或许也是因为如此重的投入,对于大模型领域内卷加剧,业界出现一种讨论,国外已经跑出了GPT-4,面对如此大的差距,国内新选手现在杀入战场做大模型,意义大不大,会不会造成人才和资源的浪费。
2023年以来,多位大佬宣布下场进行大模型创业,但是一部分人的思路已经开始调整。出门问问创始人李志飞最近多次对外表示,做大模型不能过于乐观,贸然进入难度很大,而且竞争激烈。他的思路已经从开始的做通用型大模型,转向更注重结合自身业务场景,做垂直整合大模型。
他认为,国内在1-2年之后,将会有50家以上的公司拥有自己的大模型。包括互联网大厂自研、中型互联网公司基于开源大模型微调、一些AI公司及垂直领域的甲方,都会有大模型,市场大模型的供给一定不会太少。
也有很多业界人士认为,未来大模型的发展,将会是头部几家寡头之间的竞争。
但是,中国必须做自己的大模型,已是共识。出现分歧,本质上还是因为,大模型的鏖战才刚刚开始。
民生证券相关研报指出,目前表面上大模型百花齐放,不再稀缺,是因为开源基础以及大公司本身的算力储备与资金实力,单纯发布一个大模型门槛,没有市场想象那么高。但是能够拥有高质量数据场景,才能持续迭代,性能逐步逼近ChatGPT的大模型,预计最终仍是“凤毛麟角”。市场会逐步凝结共识:得数据者得天下,数据成为大模型差异化竞争的关键。
算力、算法、数据是AI大模型研发的三大要素。大厂云们在算力上拥有一定优势。AI领域从业者贝科对深燃表示,华为布局昇腾芯片、昇腾生态已经多年,而且在各地也投资了算力中心,现如今也已经有了一定量的算力储备。阿里整个集团在GPU算力上也有一定储备。但这并不意味着大模型能力一定能持续攀升。
章容认为,大模型将带来生产力的变革,已经是毋庸置疑的事实,但是,即便是国外跑得最快的OpenAI以及微软,目前在商业化落地上已经有所进展,但也依然不能说成熟稳定。至于国内大厂的大模型,目前更是还处于非常早期的阶段。
一方面,生成式人工智能的信息安全问题已经显现。4月11日,国家互联网信息办公室发布了《生成式人工智能服务管理办法(征求意见稿)》,强调了生成内容的真实性,并且提出了相应的容错率和惩罚措施。
另一方面,当前国内市场上最新的大模型产品,无论是面向C端的体验产品,还是面向企业的接口,基本都处于内测阶段,还没有真正放开。
按照目前的形势,章容认为,当前大模型从发布走向到企业端,摸索如何真正提升生产力,至少需要半年的时间。







